Privacy Protection for Energy Data
PROBLEM:Energy Data is Private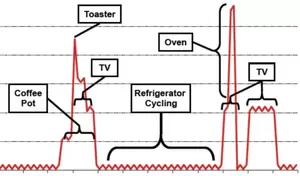
Smart meter data contains private information about energy consumers.
Intuitive privacy approaches such as 15/15 aggregation, identifier removal, and k-anonymity, have significant weaknesses. Even worse, these weaknesses are growing easier to exploit as more and varied data are collected about individuals. |
SOLUTION:
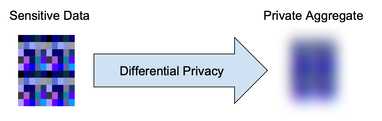
When you want to share statistics about a population, without compromising the privacy of individuals, differential privacy is the very best way to do it.
Differential privacy has emerged as the gold standard for privacy preserving statistical analysis. Energy Differential Privacy™ (EDP™) applies these methods to energy use cases. 
|
IMPLEMENTATION:
Open-Source 
Recurve has published an open-source code base that can be used to run the Energy Differential Privacy™ methods at scale.
This code repository is available to all parties without restriction under an open-source license. |
PROJECTOpen-source methods developed with input from global experts
|
METHODSEnergy specific, use-case oriented, differential privacy method
|
CODEOpen-source Python code available to all parties without restriction.
|
|
Differential privacy will revolutionize our ability to put valuable energy data to work while providing unprecedented, mathematically rigorous privacy protections to utility customers.
Many of the most valuable uses of energy data have historically been off-limits. Cities are developing plans to reduce carbon emissions without being able to actually calculate their footprints. Utility programs can’t tell the difference between a customer who needs a new AC system and one who would get the most out of lighting. Low-income programs are achieving lower than hoped impacts by treating the wrong customers. Cities are blind to the impacts of COVID on their citizens and business sectors. |

Differential Privacy primer explains the principles behind this powerful privacy technique
|
|
The way to address all of these challenges is with better energy use data. But currently, third parties can usually only access consumption data that is pre-aggregated (meaning it can’t be queried and is therefore nearly useless) or anonymized to the point where it's unusable. Most often, they can't access it at all.
At the same time, while current simple aggregation schemes to protect customer privacy may suffice when using monthly data, these approaches fall apart when looking at AMI data and hourly impacts. “Differential privacy” is an emerging best practice in which varying amounts of “noise” are added to aggregated statistics in order to mask any one individual’s contribution. |

Download the ACEEE Paper
|
Why Open Source?

Transparent
|

Replicable
|

Available
|

Stakeholder
|
|
Acknowledgments
These methods and open-source code were developed with funding from the U.S. Department of Energy, through the National Renewable Energy Laboratory, with additional thanks to the City of San Francisco, for helping to make possible this important advance. |

|
